主题
GigaBrain Challenge 2026——World Model Track 在算力自由平台的实践指南 模型训练
以 CVPR 2026 GigaBrain Challenge 大赛Workshop World Model Track 为例,记录在算力自由平台上跑通世界模型基线的关键流程与踩坑经验
一、为什么这个赛道值得关注?
在机器人和具身智能任务中,VLA(Vision-Language-Action)模型需要根据视觉观察和语言指令输出动作。传统做法通常依赖真实机器人或物理仿真器来验证策略,但真实采集成本高,仿真器又很难覆盖复杂物体交互。
World Model 的核心价值就在这里:它尝试学习“动作执行后世界会如何变化”。给定初始画面、任务指令和一段未来动作,世界模型生成后续视频帧。这样一来,它不仅能做视频生成,也有机会作为 VLA 策略的评测器或轻量仿真器。
从实践角度看,这个赛道的重点并不只是“视频好不好看”,而是生成结果是否真正跟随动作条件变化。例如机械臂是否按照给定轨迹运动,目标物体最终状态是否正确,碰撞、形变和遮挡是否合理。这些问题直接决定世界模型能不能被用来评估下游策略。
二、评测逻辑
Baseline 的评测可以粗略分成两类。
offline 更关注“给定答案条件后,视频生成得像不像”;online 则更进一步,把 World Model 放进 VLA 决策循环中:VLA 根据当前画面预测动作,World Model 根据动作生成未来画面,VLA 再继续根据生成画面做下一步决策。最后评估员观察整段由模型滚动生成的视频,判断任务是否成功。
我理解这个设定的意义在于:过去我们可能默认仿真器足够可靠,然后用它训练或评测策略;而现在的问题变成了,世界模型本身是否足够可信,能否作为一种可学习的仿真器。
三、数据集
整个数据集的组织方式比较清晰,核心可以理解为:训练、视频质量评估、闭环评估三套入口。
plain text
task/
├── train/ # 用于训练或微调
│ ├── metas/ # 任务 prompt、视频尺寸、长度等元信息
│ ├── trajectories/# 轨迹数据,例如 qpos
│ └── videos/ # 三视角真实视频
├── video_quality/ # offline 视频质量评估
└── evaluator/ # online VLA 闭环评估其中 train 是真正进入训练的数据。每个 episode 通常包含三类信息:任务文本 prompt、机器人状态轨迹,以及多视角视频。video_quality 会提供首帧和完整轨迹,用于测试条件视频生成质量;evaluator 只提供初始状态和首帧,更接近真实闭环评测场景。
这里演示了depth、videos、simulator--一种轨迹、三式视频,的样式:

任务本身覆盖了多种桌面操作,例如把香蕉放入篮子、将绿色碗放到粉色杯子上、快递封装、拆包装取薯条、扫桌面纸团、叠衣服、撕胶布贴盒子、把玩偶放入盘子等。这些任务看起来简单,但对视频生成模型来说,难点在于动作、物体状态和多视角一致性都要同时成立。
例如Task1,每次只把香蕉,放进篮子里:

四、Baseline 模型
原模型架构
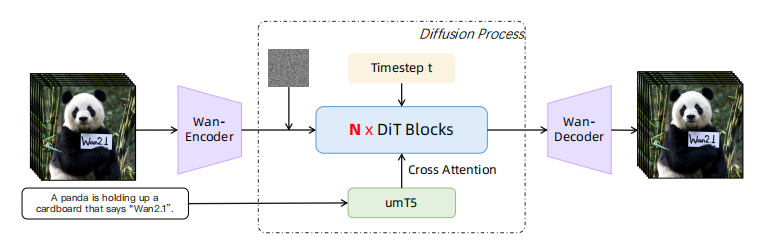
Baseline 使用的是 wan2.2-5b-diffusers。从整体结构看,可以把它理解为一个视频扩散模型:VAE 先把视频压到 latent space,Transformer 在 latent 表示上进行去噪学习,最后再由 VAE 解码回视频。
训练时,模型会对真实视频 latent 添加不同强度的噪声,并根据 timestep 学习如何把带噪 latent 还原。这里的 timestep 不是普通视频时间戳,而是扩散过程中的噪声等级。
baseline的改进架构
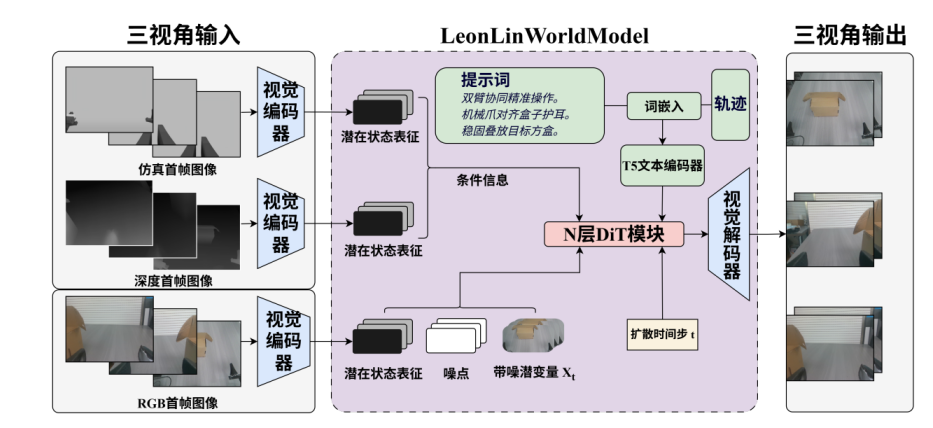
这个 Baseline 还引入了多视角、深度视频和仿真视频等条件。这样做的直觉是:真实 RGB 视频负责外观,深度和仿真信息提供额外的几何和运动线索,帮助模型更好地理解机械臂和物体之间的关系。
实践中我观察到,一个关键问题是:生成结果有时对轨迹或动作条件不够敏感。也就是说,视频看起来可能还不错,但机械臂未必严格按照给定轨迹演化。
五、数据打包:GigaDataset
原始数据里既有 JSON、pkl,也有 mp4 和图片。如果训练时每次都直接从这些分散文件中手动读取,会让 dataloader 逻辑非常混乱。GigaDataset 的作用就是把这些文件统一打包成可索引的数据集目录。
简单来说,打包过程分三步:
用
PklWriter存元数据、轨迹、标签字典等结构化字段;用
FileWriter或LmdbWriter存图片、视频路径或二进制文件;用
Dataset([...])合并多个子数据集,最后通过load_dataset(root_dir)统一读取。
最后训练时拿到的不再是一堆零散路径,而是一个 sample dict。它里面可以同时包含 prompt、qpos、三视角视频路径、深度视频路径、仿真视频路径等字段。
为了让文章不过度堆代码,数据打包的核心可以浓缩成下面这段逻辑:
python
data_dict = {
**depth_dict,
**simulator_dict,
**video_dict,
**meta_info,
"qpos": qpos,
"episode_name": episode_name,
}
label_writer.write_dict(data_dict)(https://github.com/open-gigaai/giga-datasets)
六、训练入口:GigaTrain
训练部分可以通过配置文件一键启动。真正需要理解的是它的设计方式:GigaTrain 更像一个通用训练框架,负责分布式训练、日志、checkpoint、恢复训练等通用流程;而具体任务逻辑则写在 Runner/Trainer 子类中。
以 BaselineWMTrainer 为例,它主要负责几件事:
在
get_models()中加载 VAE 和 Transformer;在
prepare_conditioning()中组织文本、图像、轨迹、深度等条件;在
forward_step()中执行 rollout 训练;在
rollout()中完成单段视频预测和 loss 计算;在
vae_decode()中把 latent 解码回可视化视频。
换句话说,配置文件负责“选什么”,Runner 负责“怎么训”。
例如启动训练:
bash
python scripts/launch_train.py \
--config_path cvpr_2026_workshop_wm_track.configs.baseline_wm_alltask.config实际配置中,重点参数如下:dst_size 决定输入分辨率,num_frames 决定总帧数,sub_frames 决定单次 rollout 的片段长度,num_views=3 表示使用三视角信息。
(https://github.com/open-gigaai/giga-train)
七、算力自由平台使用技巧
大赛官方合作伙伴算力自由平台,提供一键部署环境,直接大模型推理、仿真训练,AI 开发的高端算力。实用,方便,成本低。因为模型规模达到 5B,训练和推理都比较吃显存和 I/O。官网:https://www.gpufree.cn/
我这次实践中使用了多卡 A100 环境,但即使如此,时间和存储也需要提前规划。 平台提供多种一键开箱环境,我这里选择的是PyTorch 2.3.0 CUDA12.4-开发者镜像
经验分享
第一,尽量提前把数据集、预训练权重和 conda 环境放到平台的共享文件区。大模型任务最怕的是正式训练开始后才发现下载慢、缓存路径不对或环境重复构建。文档介绍:https://www.gpufree.cn/docs/guide/data_disk/share_data.html

第二,显式指定缓存和临时目录。视频数据和模型权重都会产生大量临时文件,如果默认写到系统盘,很容易触发空间不足。
bash
mkdir -p /data/path/tmp
export TMPDIR=/data/path/tmp平台帮助文档提供了清理系统盘的方法,请参考:https://www.gpufree.cn/docs/guide/data\_disk/clear\_sysdisk.html:
第三,训练日志和生成结果要统一放到 project_dir 下,这样后续查看 TensorBoard、找 checkpoint、整理生成视频都会更方便。例如:
python
project_dir = "experiments/baseline_wm/task4/"八、踩坑记录
1. huggingface-cli: command not found
这个竟然花了我半个小时,其间尝试用 conda install -c huggingface huggingface_hub 来排除依赖项未正常安装的问题。都无法解决。
于是准备放弃,安装其他环境去了,然后安装完 Transformers 之后 pip 给出警告称 Transformers needs huggingface_hub <= 0.34.0 while huggingface_hub == 1.0.0…
直接意识到这个船新版本的 huggingface_hub 弃用了 huggingface-cli。。。。
原来的写法类似:
bash
huggingface-cli download --resume-download可以改成:
bash
hf download这类问题本身不难,但如果只盯着“缺依赖”方向排查,会浪费很多时间。
2. VideoReader 从 torchvision.io 中不可用
另一个问题是:代码中使用了 from torchvision.io import VideoReader,但新版本 torchvision 中这个 API 已经不可用。
如果为了兼容它而强行降级PyTorch,又可能触发新版transformers对PyTorch版本的要求。
我的处理方式是:保持较新的 PyTorch 版本,同时使用 decord 替代视频读取后端。
bash
pip install decord然后把源码中的导入替换为:
python
from decord import VideoReader as TorchVideoReader